"hello!"
Se volete, usare quanto segue, ma citate la fonte.
Il lettore perdonerà quel poco di sarcasmo e la forma poco elaborata. Questo documento è un memoriale per autoriflessione, quindi in evoluzione.
A scuola si studia che le idee di Hitler hanno causato una guerra di cinque anni e venti milioni di morti. Non si dice però che la genialità di uno dei padri dell'informatica ne ha ridotto la durata di due anni, salvando quattordici milioni di vite.
L'informatica è una rivoluzione che non trova eguali nella pietra, nella pergamena e nella carta e nella storia in generale. Le macchine possono pensare, anche se limitatamente ad uno specifico compito. Svolgeranno quel compito con diligenza, senza lamentarsene, h24, preservando la stessa sensibilità. Ricordiamoci che il cucciolo di animale è operativo in pochi mesi ma non sa pensare ed è difficile da addestrare. L'uomo è capace di molto più di un animale e di un computer.
Colossus, Eniac, Edvac, non ricordo bene quale venga prima dell'altro e quale fosse americano e quale inglese. Ricordo che quello inglese aveva adottato il sistema binario perché meccanicamente era più facile da costruire e far scalare. Del resto ogni problema è scomponibile in sottoproblemi fino alla forma che richiede 2 possibili soluzioni: vero o falso. Il mondo non è solo bianco e nero ma la soluzione dei problemi a quanto pare si.
Heisemberg ha determinato che il valore di una particella e il suo cambiamento non sono misurabili contemporaneamente. Anche se questa teoria pare non essere più del tutto vera, non possiamo aspettarci di poter predirre il futuro ma solo di pianificarlo al meglio.
Personalmente ritengo che questa vada a braccetto con i teoremi di incompletezza di Gödel. Esso dice che la matematica da sola non basta a descrivere la realtà. Ci vorrà talvolta una descrizione letterale. Probabilmente è per questo che molti credono che la matematica sia un'opinione.
Tutto ciò, unitamente al difetto intrinseco della circolarità dei sistemi linguistici, ci dice che non esiste un linguaggio di programmazione migliore di un altro. Quindi bisogna cercare e assumere programmatori e non esperti in un linguaggio
Nel '700 il matematico A.Pareto, stimò che le relazioni tra gli elementi di un dominio (non ottimizzato) finiscono in rapporto 80/20 (più o meno). Il 20% del prodotto, rende l'80%. Nell'80 IBM fece proprio questo principio dichiarando che basta scrivere il 20% del codice in un linguaggio a basso livello.
Questo principio si può applicare anche all'organizzazione del codice e non solo al tipo. Facile dirsi ma ovviamente tra teoria e pratica, c'è sempre di mezzo l'applicazione pratica.
"hello!"
L'idea di astrarre per meglio concretizzare, è paradossale ma piace psicologicamente.
Sto scrivendo un memoriale sull'OOP, con dispiacere di chi mi conosce. Ma un assaggio degli effetti dell'astrazione
si trovano anche nel paragrafo "jrVSsrVSjr".
Meglio Junior o Senior? Interno o esterno? Un antipatico competente o due simpatici mediocri da plasmaare? Tutti questi possono convivere. Ciò che non sta assieme è il volere fare il minimo sforzo per il massimo risultato. Per dirla con saggezza popolare, non si può avere la botte piena e la moglie ubriaca.
La volontà non esiste. Non è mai stata misurata ne lo è. Con il minimo sforzo si può ottenere anche ii miglior disastro.
Le teorie dell'apprendimento dicono che servono almeno 3 esperienze dello stesso tipo per afferrare un concetto.
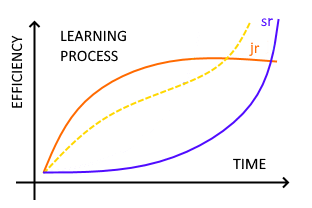
La curva gialla indica verosimilmenta cosa dovrebbe accadere in condizioni ottimali. La curva viola è riferita ad un senior, che apprende lentamente con ponderatezza per poi partire a razzo, sempre che non gli vengano tarpate le ali. Ovviamente un senior che da 30'anni programma solo in RPG sullo stesso programma, non avrà quell'andatura. La curva arancio è riferita ad un junior che apprende rapidamente per poi stabilizzarsi. Questo accade perché subisce lo stesso tarpamento di ali, perché gli mancano le basi o perché è sovra strutturato da troppa istruzione nozionistica. Vediamo un caso pratico.
Ricordo, durante l'esperienza di data-integrator, che un jr scriveva procedure di import/export in 100 righe di codice, la dove io ne impiegavo 1000. Il jr scrivava solo quanto necessario per ottenere il risultato. Io pensavo a tutto ciò che poteva andare storto. Il tempo impiegato è stato il medesimo.
Dopo qualche settimana l'Helpdesk segnalò un bug relativo al codice del jr. Dopo qualche mese un altro. Però l'azienda aveva un contratto di assistenza. Ciò costituiva anche un guadagno. La qualità richiede tempo. Dopo un anno andarono persi dei dati in maniera irrecuperabile. Dopo 10 il cliente cambiò fornitore.
Anche il mio codice non era perfetto. Nel caso peggiore però si potè ricostruire l'accaduto e recuperare i dati, grazie ai logs. In uno di questi, sarcasticamente parlando, si poneva in standby, avvisando chi di dovere di avere pazienza poiché si sarebbe presto risolto. Il difetto era che il telefono dell'HelpDesk non suonava. E' capitato infatti anche che il cliente riducesse il contratto di assistenza.
Succede anche il contrario, come al giovane mio me. Socrastrutturai un import/export creando un sistema dinamico. Mi era stato ventilata l'assunzione ma rimasi a piedi dopo sei mesi. Ero stato utile allo scopo. Fine della storia.
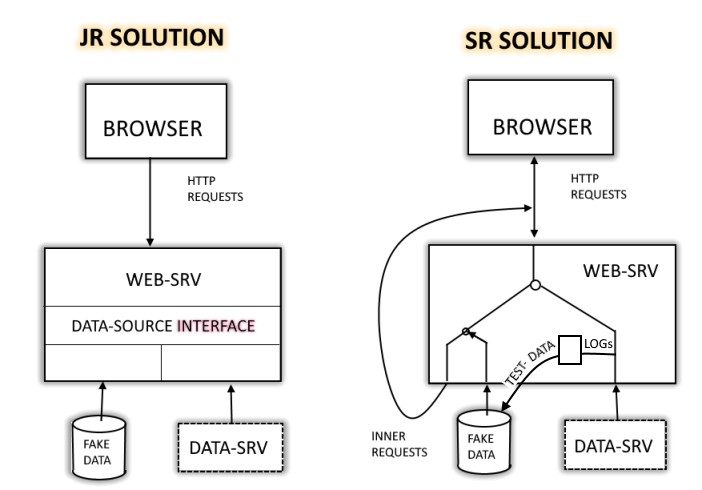
E' stato chiesto al giovane sviluppatore del modulo centrale di fornire al client informazioni d'esempio, per sopperire alla latenza dello sviluppo del server.
Essendo tale l'inprinting dei suoi docenti o di qualche documento di evangelizzione di una delle case informatiche dominanti, la soluzione è concettualmente corretta. L'esecuzione lo è stata formalmente altrettanto. Al lato pratico però, una volta arrivato il server, è diventata sovra-strutturazione d'intralcio per gli immancabili cambiamenti.
Nel diagramma di destra c'è la soluzione che avrei pensato io. Avrei riciclato letteralmente, anziché astrattamente, il codice preesistente. La prima soluzione è efficacie. La seconda è efficiente. Quest'ultima è basata sul concetto del LoadBalancing ed è quindi fuori dallo schema concettuale. Irrazionale ma non irragionevole.
Avrei poi predisposto i logs in modo che, una volta pronto il server, questi sarebbero diventati cibo per i tests automatici.
Sono altre poi le osservazioni che si potrebbero fare sulla carenza progettuale e l'assenza di retrospettiva. E' un'altra storia interessante.
Quante parole spese su questo tema. Certamente abbiamo capito che i giudizi sono da evitare. Non possiamo commentare 2.000.000 di righe di codice. Il codice è per sua natura (di linguaggio) auto-esplicante. Ma i nomi che vengono impiegati possono indurre in errore. Non ha senso chiamare una variabile "FieldIndexOfSourceTable" in un contesto di 10 righe di codice. Basterebbe "i" o "idx" ma i più blasonati manuali fanno venire voglia di programmare in COBOL, anziché scrivere una riga di commento per ogni riga di codice.
"Chiudere la porta" è un comando che non esprime il processo. Poiché la mia auto è vecchiotta, ho spiegato a moglie e figli di "accompagnarla fino a 10cm dalla chiusura e poi chiuderla". Questo esempio ha delle implicazioni con l'impiego delle risorse, l'importanza della documentazione e il Pair Programming.
L'apporto dell' informatica non comporta lo stesso meccanismo che è servito alla pergamena per sostituire le tavole di pietra e alla carta per sostituire la pergamena. Sebbene la digitalizzazione riduca i costi a 1/10, aumentano i costi del processo. I software per il lavoro documentale come Word e Excel sono oggi dispersivi e superati dal Web e ancor di più dal cloud.
Nella mia lunga esperienza, ho rivestito diversi ruoli in diverse aziende. Sono stato diretto e ho diretto e poi sono stato ancora diretto.
Grazie a questa multipla e dicotomica esperienza, ho notato che dirigendo si chiede agli altri cervelli di funzionare diversamente da come sono abituati. Questo è già un fattore di inefficienza. Per attuare quest'operazione, bisogna fare formazione diretta o delegarla. Questo pone le risorse in ordine seriale anziché parallelo ed è altro fattore di inefficienza. La formazione non è proprio abitudine italiana. Per praticità poi preferiamo dare informazioni orali senza aspettarci feedback e aggiungiamo altra inefficienza. Scritte o orali che siano, se non si sa scrivere bene, si può dare delle indicazioni intendendo altro. Così si creano facili bersagli e capriespiatori, finendo per perdere le risorse che con tanta difficoltà è stata trasformata in ciò che non era.
Ho notato troppo spesso la presenza di gelosia per le informazioni. I motivi erano diversi:
Questo perché si produrrà un processo di lavoro seriale più che parallelo. Si creeranno poi tutta una serie di ambiguità che, andando a braccetto con la nostra cultura catto-latina del senso di colpa, individuerà facili bersagli e capri espiatori.
Sbagliando si impara perché ci si approssima alla verità. L'errore vero consiste nel ripetere gli stessi sbagli. Chi cercherà di cambiare lo status quo sarà facile bersaglio.
Ciò porta al turn-over, con perdità del knowhow e degli sforzi per l'individuazione degli strumenti. Il che agevolerà la preservazione dell'importanza dei soliti. Il cerchio si chiude e la storia si ripete fino a quando fattori esterni di enorme portata non produrranno un cambiamento forzato.
Il cervello è il nostro socio. Lui guida l'automobile mentre noi pensiamo ad altro. Lui pensa a quello che noi vogliamo dire. Non abbiamo il manuale. Non sappiamo ancora come funziona. Sappiamo che se srotolato, occupa la distanza di A/R tra Terra e Luna. Sappiamo che il computer più potente del mondo raggiunge il 4.5% della sua potenza.
Il seguente disegno è una mappa spontaneamente prodotta dal mio cervello relativamente ad una situazione. Analizzandolo vi trovo un incredibile concentrato di informazioni relative al passato, presente e futuro.
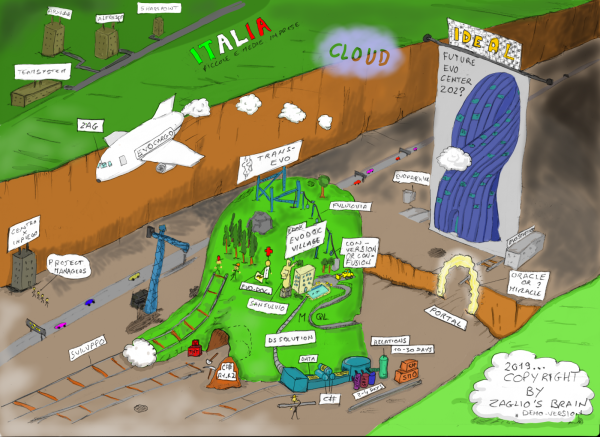
Se si trovasse il modo di poter creare una simile mappa cooperativamente, le potenzialità di un gruppo di lavoro aumenterebbero esponenzialmente.
Funziona. Dicono faccia risparmiare il 30%. Si, nel mondo "organizzato" anglosassone, nel mondo "italiano" latino, arriverà anche al 50%.
La teoria dei sistemi dice che:
"Do Not Repeat Yourself" e "Keep It Simple And Stupid" sono capi saldi della programmazione. C'è chi si spinge oltre con "non commentate il codice, riscrivetelo" ossia scrivere codice autoesplicante (poiché è scritto è già tale, forse il riferimento è ad altro). Vedremo degli esempi.
Quando la programmazione era solo strutturata e lo sviluppo software partiva quasi dal nulla, il programmatore doveva necessariamente sviluppare diligenza e chiudere tutto ciò che apriva.
Poi vennero il Garbage Collector e nuovi paradigmi di programmazione astratta che ancora oggi promettono al programmatore di poter dimenticare tutta una serie di fastidiosi doveri. Il concetto dell'OOP nasce da un'idea di Alan Kay che ha dichiarato di non aver mai pensato ad un linguaggio. Il suo accostamento alla biologia era solo un'analogia. La biologia tratta più di due o tre livelli (classe/istanza o modello/classe/interfaccia). Con famiglia, regno e quant'altro ne ha almeno nove. Ogni semplificazione implica una riduzione e ogni obbligo è anche un impedimento.
Nel linguaggio delle LEGO, se i mattoncini rappresentano il carattere e la loro combinazione forma la personalità. Se funzioni e tipi base sono i mattoncini. Le LEGO moderne sono più bene in quanto più vicine al prodotto rappresentato. L'aumento dei micro-pezzettini e la loro specializzazione ha ridotto la creatività. Probabilmente si possono fare anche più cose, ma è richiesta maggiore creatività ed immaginazione. Ciò scoraggia l'inventiva.
Quando ho cominciato questo mestiere, le CPU erano a 4Mhz e i computer avevano 16KB di RAM, grafica inclusa.
S = "", I = 0 WHILE ( I++ < 5000000 ) DO S = S + "0123456789"
Questo semplice programma esegue il concatenamento di 10 caratteri per 5 milioni di volte. Richiede solo 1/1000 della memoria di cui sono dotati i computer moderni. E' un esempio forzato, ma su un processore a 3GHz, verrebbe eseguito in un millesimo di secondo (1/3000000000*5000000).
In pratica arriverà invece a saturare anche un computer potente, poiché quella che dovrebbe essere un concatenamento (progressivo) è in realtà una somma, ossia un'operazione ripetitiva che si porta dietro il pregresso.
Il C++ capisce che la somma è un concatenamento ed ottimizza. C# NON lo faceva, almeno fino alla versione 6. Vorrei sapere se Haskell lo fa e come risolve questa situazione.
Chi NON ha esperienza di programmazione a basso livello, potrebbe non scoprirlo mai, concludendo che sia necessario scalare l'hardware.
Questo problema affligge maggiormente nell'uso di oggetti e la dove ci sia gestione di memoria con il Garbage Collector.
Prima dell'OOP si vedeva codice tipo:
if action = costante then
else if action = ...
Dopo l'OOP si vede codice tipo:
if typeOf action is ....
Vedo spesso usare il GUID come chiave per ovvie ragioni di unicità. E' utile soprattutto in previsione di una sincronizzazione tra sistemi diversi anche se appartenenti alla stessa soluzione (es. mobile<->server). Anche questa è una soluzione psicologicamente di comodo. Un INT indirizza quattro miliardi di records ed è più che sufficiente.
Quel che un programmatore sa è che un INT occupa 4bytes e un GUID 16bytes. Può non sapere che un processore a 32 ha una word di registro che contiene l'INT ma ne deve impiegare 4 per un GUID. Ciò vuol dire che (sempre esempio forzato), un processore a 3GHz potrebbe gestire 3 miliardi di ID di tipo INT al secondo. Diventano 700 milioni in caso di GUID. Ovviamente sappiamo che già questo numero va ben oltre la realtà.
Le implicazioni sono tante. Ho potuto però dimostrare ai membri del mio team che una sincronizzazione PDA/SERVER che mandava in crash il PDA con 3000 records con GUID, raggiungeva i 15000 con l'INT. Poi abbiamo risolto mandando l'intero archivio, ma non ho detto loro che si poteva migliorare di un fattore 10 le prestazioni con un semplice [segreto].Rimanendo in tema databases, mi è capitato tanto di dover spiegare cosa e come aggiungere indici, quanto perché toglierli o fare a meno. Se da una parte è abbastanza intuibile che un indice appesantisce la fase di scrittura, si pensa meno che una scrittura può implicare una lettura. Figuriamoci in ambiente ad alta concorrenza, magari su server monolitico.
Per questioni di scelte progettuali, questo problema può rendere addirittura un prodotto gratuito come Postresql più interessante di una licenza MSSql Server Enterprise da 150.000€.
Ma quel che sfugge per carenza di knowledge base (KB) è che una lettura tramite indice può sfociare certamente in una letura diretta di una pagina, ma questa è come sparpagliata in una stanza assieme alle altre. Vediamo la grafica.
La figura 1 è una raffigurazione convenzione di indice a sinistra e tabella a destra.
 fig.1
fig.1
Nel vecchio dBase, queste due strutture costituivano due files. Oggi finiscono in un unico file rappresentabile come in figura 2.
 fig.2
fig.2
La figura 2 verrebbe utile per far capire perché MSSQL richiede meno risorse di Oracle ma allo stesso tempo degrada esponenzialmente in performance. Non è questo però l'oggetto del paragrafo.
Questa vista logica, nella realtà diventa qualcosa di simile alla figura 3.
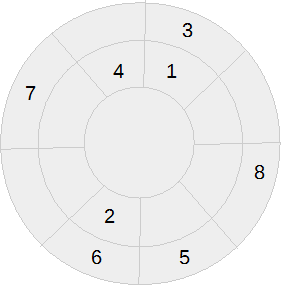 fig.3
fig.3
Ricordo che sono delle rappresentazioni forzate. Lo sparpagliamento può essere minore, grazie alle proprietà del file system o alle capacità del sistema operativo ma può essere anche maggiore a seconda della configurazione software o hardware. Quando non sono HP e Oracle a lavorare assieme, spesso le configurazioni software e hardware non c'entrano nulla l'una con l'altra.
Questo vale sia per SQL che noSQL. Già qualche sostenitore del noSQL si sta ricredendo. Ne ho visti tanti di entusiasmi smorzarsi dopo il primo decennio. Se ci sono più di 800 linguaggi di programmazione ma il C rimane tra i primi 10 più usati, ci sarà un motivo. Mi stupisce sempre sentire di performance eccelse di strumenti quali ad esempio Node.js. Azzarderei a dire che le performance di sviluppo sono inversamente proporzionali alle prestazioni di runtime.
Per un'analisi di differenza di normalizzazione in caso di un Document System Management, seguire questo link
10 piccole query su mono processo possono essere più veloci di una query complessa ottimizzata in automatico dall'engine su CPU multithread.
La seguente immagine rappresenta la classica scelta di relazione 1 a MOLTI per la gestione di un software documentale. Un record è legato a molti documenti. Ogni documento ha delle proprietà.
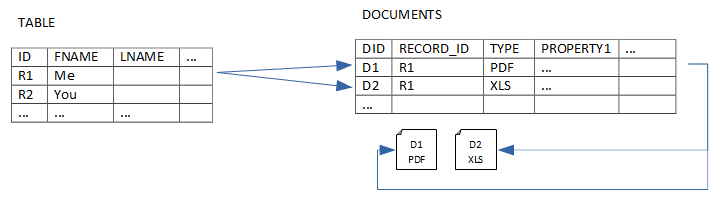
La rappresentazione di questa struttura pone però i documenti in linea con il relativo record. Quindi se la verticalizzazione consente l'associazione di un numero infinito di documenti, nella pratica il numero impiegato è limitato.
La seguente struttura sacrifica il principio di normalizzazione in nome di un uso pratico, ccontenuto, non limitato, più performante e flessibile.
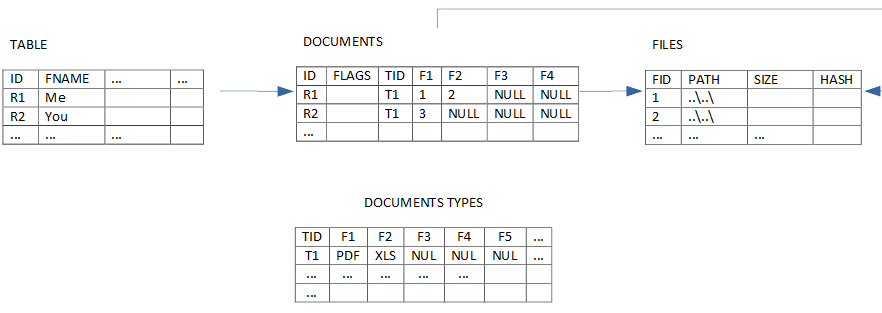
"L'organizzazione di un'azienda è inversamente proporzionale al numero di fogli XLS che usa."Questa non è mia, ma la sottoscrivo. Se già rigide strutture possono contenere dati assurdi tramite campi sovradimensionati o note, figuriamoci cosa può fare una cella Excel che può cambiare natura. Sfortunatamente in un periodo in cui molti individui sono quantitativamente troppo istruiti, dimentichiamo che una piccola differenza di qualità fa una grande differenza nel lungo periodo.
Una soluzione "smart" può sembrare frutto di genialità e creatività, ma potrebbe solo gestire il problema senza risolverlo.
TRY
VARIABILE = ALTRA_VARIABILE
END TRY
Abbiamo visto tutti almeno una volta usare eccezioni a modo di: "Chissenefrega, basta che non si spacchi che puoi vendere bugs come fossero features":
Ho visto programmi C++ che facevano un uso raffinato dei templates (AGG). Al momento di usarli ho lasciato perdere. Troppo complessi. Poi mi sono accorto anche che quando il gioco si fa duro, solo l'hardware può giocare e non c'è ottimizzazione software che possa competere.
Ho visto programmi fare uso di interface in maniera magistrale, in un potpourri di codice auto esplicante. Poi è arrivato il neolaureato con esperienza. Il NcE esiste per convenzione del 60% degli annunci di ricerca italiani. In barba ad Heisemberg viene assunto da selezionatori Nce. Naturalmente c'è un referente che sa tutto ma non dice niente e non ha mai avuto il tempo di scrivere l'ABC. Altro che metodo Toyota o principio 80/20. Tra teoria e pratica non c'è nient'altro che un muro.
Fresco di tutte le sante neo teorie accademiche, il nostro NcE guarda il problema diritto negli occhi e capisce che ha bisogno di weaponX(). Funzione, classe o metodo che sia, la implementa. Un colpo al cerchio e uno alla botte e va che è un piacere. Quando diventa esperto anche dell'applicazione, scopre che esisteva già e si chiamava weapon_YX(). Ormai è tardi per riscrivere il codice perché c'è un nuovo problema all'orizzonte o addirittura un nuovo lavoro. Così il nuovo NcE wrappa weaponX su weapon_YX giusto per mettere un poco di ordine senza sconvolgere. Poi arriva il nuovo-nuovo NcE.
Ho visto usare prefissi "XXX_","AAA_" e altro alle tabelle temporanee dove avevo imposto il prefisso TMP. Alla fine l'azienda ha preferito fare a meno di me e investire il ricavato in altri apprendisti. Tutto questo mentre stavo sviluppando triggers DDL che istruissero gli apprendisti all'uso corretto di nomi e commenti, senza perdere tempo a scrivere documentazione che nessuno legge o gli viene dato il tempo per farlo.
Ho visto banali "SELECT qualcosa FROM tabella WHERE condizione" seppellite sotto strati e strati di codice da far piangere (è la nuova programmazione a cipolla), 10 passaggi, alcuni ricorsivi, di 30 istruzioni, equivalenti ad 1 passaggio di 10 istruzioni SQL92.
Ho visto professionisti(che di fatto sono solo lavoratori autonomi) scrivere codice inutilmente suvrastrutturato, perché erano abituati così e quindi per loro era più facile e veloce.
Ho visto utenti dichiarare che il programma aveva dato errore X ma senza visualizzare il messaggio.
Ho visto tanti workaround di difetti di progettazione produrre qualcosa tipo un jumbo con i freni di una bicicletta.


Ho lavorato alla manutenzione di 2.000.000 di righe di codice scritto con tutti i crismi OO e dei patterns & C.. e mi sono chiesto se sia più facile cercare una scatola tra 4.000.000 disposte in piano ad array, oppure una in 2.000.000 disposte a piramide, che per di più contiene solo un riferimento astratto alla vera scatola.
Ho inseguito oggetti dentro metodi annidati che ritornavano un oggetto result. Messi in fila farebbero:
Return(Return(Return(Return(Return(Return(Return(object)))))))Poi ho dovuto fare una modifica al 4° livello. Questa richiedeva il risultato per sapere se andare oltre. Si, lo so, non si capisce. Immaginate di essere al 4° piano di un edificio e di dover salire all'ultimo per sapere se potere proseguire oltre il 4°.
Per quanto sopra (frammentazione del codice o mal progettazione) e per questioni di sicurezza (con tutta la gente che si assume e se ne va), si sono resi necessari i sistemi automatizzati di compilazione e test. Proprio come facevo 25 anni fa quando programmavo in C, anche se ero da solo.
A quel tempo le grosse applicazioni si dividevano verticalmente in librerie e orizzontalmente in chunks di funzioni. Oggi ci sono i namespaces e le classi ma dobbiamo mettere i progetti nei posti sbagliati solo perché le soluzioni non prevedono links simbolici.
Testare è una scienza o un'arte? Mi chiedo questo perché la scienza sa di non sapere ciò che a volte i tests presuppongono di conoscere.
Ho usato questa regola per anni, assieme alla teoria dei sistemi, per raggiungere gli obiettivi nei tempi e costi stimati, senza ritrovarmi grossi problemi in post produzione. I programmi come G-Marmo, Tavolinux e SAP Connector che sono sopravvissuti o sopravvivono per otto o più anni senza modifiche, ne sono una testimonianza.
Il seguente esempio è tratto dal testo "Clean Code". In alto a destra c'è il codice d'origine. A sinistra la revisione dell'autore. In basso a destra la mia versione.
L'autore spezza il funzioni più piccole, auto-esplicanti. Non tutti i linguaggi consentono nested functions. Una classe non avrebbe senso (figuriamoci condita di interfaces :-)
La mia versione sembra scritta da un bambino ordinato, ma fa di più. Sempre per il principio di Heisemberg, non si può ottimizzare sia per tempo che per spazio. Quindi ho usato "più memoria" replicando parti di stringa, in violazione del principio DRY. Il codice è più compatto, leggibile, capibile dai vecchi come me e dai NcE. Con il tempo risparmiato, ho aggiunto l'internazionalizzabilità.
Rimane incasinabile ma lo trovo improbabile. Si fa prima a rifare tutto, riciclando questo codice come pseudo-code.
Ho detto di aver violato il principio DRY ma ritengo che, a livello strutturale, lo è anche fare più funzioni. La mia violazione del DRY preserva il KISS.
// "Clean code" (pg. 28,29)
private
void printGuessStatistics(
char candidate, int count
)
{
string number;
string verb;
string pluralModifier;
public string make(
char candidate, int count
)
{
createPluralDependentMessageParts(count);
string guessMessage = string.format(
"There %s %s %s%s",
verb, number, candidate,
pluralModifier
);
print(guessMessage);
}
private
void createPluralDependentMessageParts(
int count
)
{
if (count == 0) thereAreNoLetters();
else if (count == 1) thereIsOneLetter();
else thereAreManyLetters(count);
} // createPluralDependentMessageParts
private
void thereAreManyLetters(int count)
{
number = integer.toString(count);
verb = "are";
pluralModifier = "s";
} // thereAreManyLetters
private
void thereIsOneLetter()
{
number = "1";
verb = "is";
pluralModifier = "";
}
private
void thereAreNoLetters()
{
number = "no";
verb = "are";
pluralModifier = "s";
} // thereAreNoLetters
} // printGuessStatistics
// the original code
private
void printGuessStatistics(
char candidate, int count
)
{
string number;
string verb;
string pluralModifier;
if (count == 0) {
number = "no";
verb = "are";
pluralModifier = "s";
} if (count == 1) {
number = "1";
verb = "is";
pluralModifier = "";
} else {
number = integer.toString(count);;
verb = "are";
pluralModifier = "s";
}
string guessMessage = string.format(
"There %s %s %s%s",
verb, number, candidate,
pluralModifier
);
print(guessMessage);
}
// my revision
void printGuessStatistics(
char candidate,
int count
)
{
string msg;
if (count == 0)
msg = TR("There are no {0}s",candidate);
else if (count == 1)
msg = TR("There is 1 {0}",candidate);
else if (count > 1)
msg = TR("There are {0} {1}s", count, candidate);
print(msg);
} // printGuessStatistics
Ho iniziato a 13 anni da autodidatta. Non sono un genio, è solo passione. Dopo un mese, il BASIC già mi stava stretto. Ho così appreso l'assembler Z80 e le fasi di trasformazione di un codice sorgente in binario, o linguaggio macchina. Qualche mese fa mio figlio, in prima elementare, mi ha stupito nel saper fare conti complessi ma si bloccava chiedendogli di procedere passo passo, togliendo o aggiungendo 1, N volte. Ricordo con piacere il registro A dello Z80. A sta per accumulatore. Penso che dovremmo introdurre la programmazione dalla prima elementare come già fanno all'estero. Benedetto sia Faggin, padre del processore. Se me ne desse la possibilità lavorerei per lui come Hari Seldom fece per R. Daneel Olivaw.
Leggendo il libro slla storia di Turing, capisco che la famosa macchina di Turing è qualcosa che va oltre la mia umile immaginazione. Mi limiterò a ricordarne l'aspetto tecnico-pratico. Sostanzialmente questa prende ad uno ad uno una serie di codici che rappresentano nomi, valori e operazioni. Queste assegnano i valori ai nomi e operano dei confronti. Sulla base del risultato, si può assegnare un valore ad un nome speciale, il Contatore di Programma. Questo indica il punto successivo in cui la serie deve proseguire. Con ciò si ottiene una macchina universale.
Classico esempio:
vm = {
fname,lname: string
fullname => fname + ' ' + lname
}
Supponiamo di voler legare l'attivazione di lname alla valorizzazione di fname. Il legame non è più tra i membri del modello ma esce ed entra nel modello grafico, che è ciò che avviene automaticamente tra fullname e il suo controllo.
fname.subscribe(
f(value) {
controlOf(lname).disabled = (value == "")
}
}
Altrimenti sarebbe stato:
controlOf(fname).onCHANGE = f() {
controlOf(lname).disabled = ( controlOf(fname).value == "" )
}
Quale'è la differenza? Che il primo è legato allo stato, il secondo all'evento. Il primo caso, oltre a richiedere meno codice, funziona anche con:
fname = ""
Mentre:
controlOf(fname).value = ""
Non fa scattare l'evento keyPRESS a cui potrebbe essere legato l'onCHANGE.
Oggi la n.u. non ha più senso perché gli IDE ci aiutano ad identificare il tipo di identificatore.
In realtà forse non l'ha mai avuta perché le capacità mentali dei più sono limitate e il problema va necessariamente diviso in sottocontesti piccoli a sufficienza da consentire di chiamare le variabili i,k e n.
Eppure c'è chi ancora la usa quasi come se nella sua testa si parlasse in terza persona:"Lei adesso si trova in una variabile di tipo Classe" e quindi abbiamo "clsVar = new Class;".
06.08.2018 Stefano Zaglio
_______________________________________________________________________ Fonti bibliografiche "Software sytems, failure and success" Pattersons, C.Jones "Clean code" Prentice Hall, R.C.Martin "Programmazione orientata agli oggetti" Addison Wesley, Brad J.Cox "Pragmatic Programmer: From Journeyman to master" Addison Wesley,A.Hunt, D.Thomas “Tinycc-devel - mailing list” "Da software house a impresa di servizi" Mondadori, M.Bolognani "Dai sistemi al pensiero sistemico" FrancoAngeli, P.Mella "Oltre la qualità totale" FrancoAngeli, G.Dellacasa, S.Moncini "Il principio 80/20. Il segreto per ottenere di più con meno" FrancoAngeli, R.Koch "Usiamo la testa" e "Mappe mentali" Frassinelli, Tony Buzan "Change" Astrolabio, P.Watzlawick, J.H.Weakland, R.Fish "Perchè non possiamo non dirci darwinisti" Rizzoli, E.Boncinelli (2009) "Il computer di Dio" e "Il diavolo in cattedra" di Piergiorgio Odifreddi (2000-2003) "Verso un'ecologia della mente" Adelphi, G.Bateson (1977) “Sviluppare il pensiero nel ritardo mentale” Erickson, P.L. Baldi "L'arte di imparare" Mondadori, B.Carey [1]Esperienza personale